Velocity: TCP and the Lower Bound of Web Performance
John Rauser (Amazon) was my favorite speaker at Velocity. His keynote on Creating Cultural Change was great. I recommend you watch the video.
John did another session that was longer and more technical entitled TCP and the Lower Bound of Web Performance. Unfortunately this wasn’t scheduled in the videotape room. But yesterday Mike Bailey contacted me saying he had recorded the talk with his Flip. With John’s approval, Mike has uploaded his video of John Rauser’s TCP talk from Velocity. This video runs out before the end of the talk, so make sure to follow along in the slides so you can walk through the conclusion yourself. [Update: Mike Bailey uploaded the last 7 minutes, so now you can hear the conclusion directly from John!]
John starts by taking a stab at what we should expect for coast-to-coast roundtrip latency:
- Roundtrip distance between the west coast and the east coast is 7400 km.
- The speed of light in a vacuum is 299,792.458 km/second.
- So the theoretical minimum for roundtrip latency is 25 ms.
- But light’s not traveling in a vacuum. It’s propagating in glass in fiber optic cables.
- The index of refraction of glass is 1.5, which means light travels at 66% of the speed in glass that it does in a vacuum.
- So a more realistic roundtrip latency is ~37 ms.
- Using a Linksys wireless router and a Comcast cable connection, John’s roundtrip latency is ~90ms. Which isn’t really that bad, given the other variables involved.
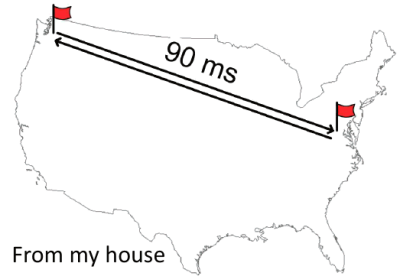
The problem is it’s been like this for well over a decade. This is about the same latency that Stuart Cheshire found in 1996. This is important because as developers we know that network latency matters when it comes to building a responsive web app.
With that backdrop, John launches into a history of TCP that leads us to the current state of network latency. The Internet was born in September of 1981 with RFC 793 documenting the Transmission Control Protocol, better known as TCP.
Given the size of the TCP window (64 kB) there was a chance for congestion, as noted in Congestion Control in IP/TCP Internetworks (RFC 896):
Should the round-trip time exceed the maximum retransmission interval for any host, that host will begin to introduce more and more copies of the same datagrams into the net. The network is now in serious trouble. Eventually all available buffers in the switching nodes will be full and packets must be dropped. Hosts are sending each packet several times, and eventually some copy of each packet arrives at its destination. This is congestion collapse.
This condition is stable. Once the saturation point has been reached, if the algorithm for selecting packets to be dropped is fair, the network will continue to operate in a degraded condition. Congestion collapse and pathological congestion are not normally seen in the ARPANET / MILNET system because these networks have substantial excess capacity.
Although it’s true that in 1984, when RFC 896 was written, the Internet had “substantial excess capacity”, that quickly changed. In 1981 there were 213 hosts on the Internet. But the number of hosts started growing rapidly. In October of 1986, with over 5000 hosts on the Internet, there occurred the first in a series of congestion collapse events.

This led to the development of the TCP slow start algorithm, as described in RFCs 2581, 3390, and 1122. The key to this algorithm is the introduction of a new concept called the congestion window (cwnd) which is maintained by the server. The basic algorithm is:
- initalize cwnd to 3 full segments
- increment cwnd by one full segment for each ACK
TCP slow start was widely adopted. As seen in the following packet flow diagram, the number of packets starts small and doubles, thus avoiding the congestion collision experienced previously.
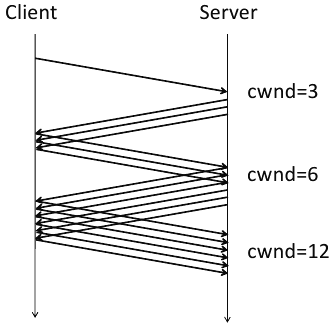
There were still inefficiencies, however. In some situations, too many ACKs would be sent. Thus we now have the delayed ACK algorithm from RFC 813. So the nice packet growth seen above now looks like this:
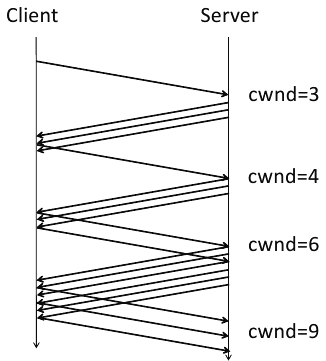
At this point, after referencing so many RFCs and showing numerous ACK diagrams, John aptly asks, “Why should we care?” Sadly, the video stops at this point around slide 160. But if we continue through the slides we see how John brings us back to what web developers deal with on a daily basis.
Keeping in mind that the size of a segment is 1460 bytes (“1500 octets” as specified in RFC 894 minus 40 bytes for TCP and IP headers), we see how many roundtrips are required to deliver various payload sizes. (I overlaid a kB conversion in red.)
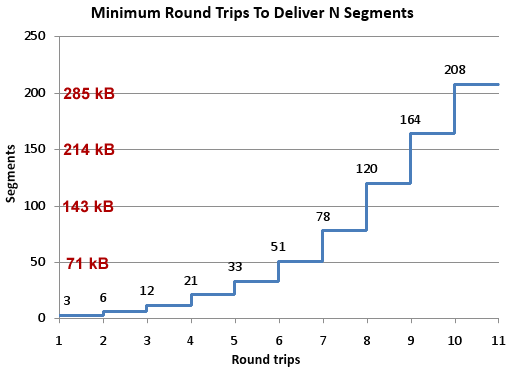
John’s conclusion is that “TCP slow start means that network latency strictly limits the throughput of fresh connections.” He gives these recommendations for what can be done about the situation:
- Carefully consider every byte of content
- Think about what goes into those first few packets
- 2.1 Keep your cookies small
- 2.2 Open connections for assets in the first three packets
- 2.3 Download small assets first
- Accept the speed of light (move content closer to users)
All web developers need at least a basic understanding of the protocol used by their apps. John delivers a great presentation that is informative and engaging, with real takeaways. Enjoy!
Mike Bailey | 14-Jul-10 at 4:45 am | Permalink |
I’ve got video with the end of the talk and am stitching it together now. I hadn’t realized my previous attempts to combine the videos had failed.
I’ll update the post that currently shows the truncated video when I’ve got the new file uploaded.
http://mike.bailey.net.au/blog/?p=39
Mike Bailey | 14-Jul-10 at 11:55 am | Permalink |
The video now includes the final 7 minutes of John’s talk.
http://mike.bailey.net.au/blog/?p=39
Steve Souders | 14-Jul-10 at 12:08 pm | Permalink |
Thanks Mike!
Daniel Krsicka | 15-Jul-10 at 1:17 am | Permalink |
Even if many other factors participate on overall web app latency, I must confirm all what’s here. And I’m glad to read this kind of article because from my experience only a small amount of developers know something more about network protocol stack.
What’s obvious but interesting to read in black and white is that latency of small frame/packet/segment on metalic or optical fiber is the same as before 15 years :-). IT proffesionals live in world where everything change day by day. It can suprising that physical principles stay the same :-).
Roland Dobbins | 15-Jul-10 at 3:21 am | Permalink |
In addition to NVP, packet-regeneration times at each hop must be taken into account, as well.
Dana Andrews | 15-Jul-10 at 6:22 am | Permalink |
What do you mean Willis ‘2.2 Open connections for assets in the first three packets’? Is this like pre-loading images in javascript etc?
Steve Souders | 15-Jul-10 at 7:49 am | Permalink |
@Dana: This is flushing the document early.
Billy Hoffman | 15-Jul-10 at 9:44 am | Permalink |
I would add another takeaway from John’s excellent research: new, HTTP connections are *very* expensive. Creation involves a 3-way handshake, and then you have slow-start. Developers should check to make sure their application code, CMS, or inline devices aren’t adding “Connection: closed” headers.
Me, my self and I | 15-Jul-10 at 10:10 pm | Permalink |
Idunno. IMO, app responsiveness is a matter of design. Nowadays browsers and the HW platforms they’re running on allow moving quite a lot of the logic to the client. IMO, the best approach of creating responsive apps isn’t in optimizing the low level design of the data transfer layer, but moving most of the logic to the client, and have the client only communicate seldomly with the server, asynchronously, if possible, even if transferring large chunks of data at a time. The user won’t mind waiting a few seconds for a large form to be submitted – he’s used to wait a few seconds to save a large document or spreadsheet. But he surely will mind if each and every click needs half a second to be processed, because it is being processed server-side.
Cthulhu | 21-Jul-10 at 7:31 am | Permalink |
So, next to flushing early as Steve suggests, how can a web developer like me influence the order at which external resources (images, css etc) is downloaded? It makes sense that this happens sequentially, but that means that you can only have the browser download CSS and JS and other HEAD-resources before it downloads things like images – which may be smaller than CSS / JS and such.
Maybe sending a list of resources (+ their type and size) before or while sending the HTML (or whatever content) would be a worthwhile addition to the various internet standards. This’ll allow the browser itself to start downloading external resources (and prioritize them) while also downloading the HTML and other bits of the site. That is, if that really makes such a big difference.
Reed Hedges | 20-Sep-10 at 10:07 am | Permalink |
Please don’t abandon a periodic blog post. It could be a summary of a week’s tweets or something… but reform them into sentences and paragraphs in that case, not just copy them, please :)
Will Alexander | 09-Dec-10 at 9:22 am | Permalink |
This page has an excellent animation that demonstrates the effect of slow-start and window scaling
http://www.osischool.com/protocol/Tcp/slowstart/index.php
Johann | 03-Feb-11 at 2:13 pm | Permalink |
I’ve just tried to reproduce this with wget and Wireshark but I have not seen the delayed ACK behavior above but always one ACK for each packet.
Is this only happening on a certain operating system? (I’m using Linux)
Thanks