HTTP Archive: past and future
Background
The HTTP Archive crawls the world’s top 500K URLs twice each month and records detailed information like the number of HTTP requests, the most popular image formats, and the use of gzip compression. We also crawl the top 5K URLs on real iPhones as part of the HTTP Archive Mobile. In addition to aggregate stats, the HTTP Archive has data (including waterfalls, filmstrips and video) for individual websites, for example, Apple, CNet, and YouTube.
Pat Meenan and I started the project in 2010 and merged it into the Internet Archive in 2011. The data is collected using WebPagetest. The code and data are open source. The project is funded by our generous sponsors: Google, Mozilla, New Relic, O’Reilly Media, Etsy, Radware, dynaTrace Software, Torbit, Instart Logic, Catchpoint Systems, Fastly, and SOASTA mPulse.
Past Year
Pat and I are always working to improve the HTTP Archive in terms of reach, metrics, and features. Here are some of the major achievements over the past year.
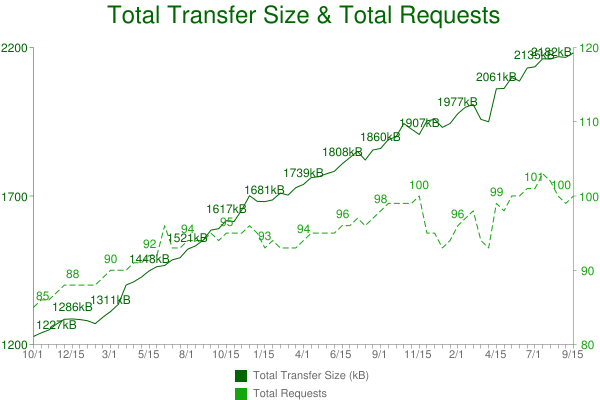
500K URLs: One of the most apparent changes in the last year is the increase from 300K to 500K URLs tested on desktop (using IE9). These are the world’s top URLs based on the Alexa Top 1,000,000 Sites. Our goal is to reach 1 million on both desktop and mobile.
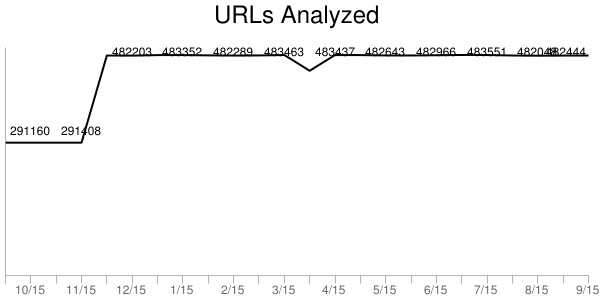
New Hardware: Adding more URLs was possible when we upgraded our hardware adding a Supermicro 2U quad node server and ten Samsung 850 Pro 1TB SSDs. This added enough test capacity and storage to increase to 500K URLs. This new setup should be enough to allow us to go to 1 million URLs on both desktop and mobile once we settle on test environments. (More on that later.)
New Sponsors: In the past year Fastly and SOASTA mPulse joined our illustrious array of sponsors. This was critical in terms of finances since the new hardware greatly reduced our savings. Just last month we had to replace the SSDs on our original server and the funds from these new sponsors made that repair possible. Many thanks to all of the HTTP Archive sponsors for making this project possible.
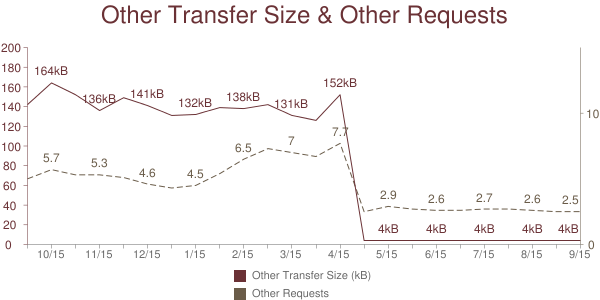
Better Content Types: We improved how responses are classified into content types. The Content-Type response header is incorrect about 5% of the time, and these used to be classified as “other”. Now most of the “other” responses are given one of these new content classifications: video, audio, xml and text. As a result, the number of “other” responses dropped dramatically when this change was rolled out in April 2015.
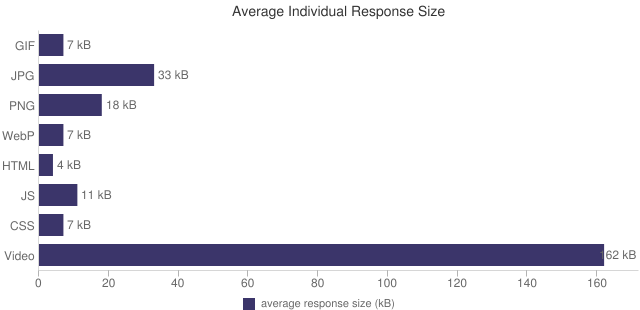
New Formats:Â In addition to improving content type classification, we added new code to detect the format for images (gif, jpg, png, webp, ico, & svg) and video (flash, swf, mp4, flv, & f4v). This allows us to do deeper comparisons of new formats such as WebP as shown in the chart below.
Chrome: From the inception of the HTTP Archive the goal was to do our testing on the browser version used by the most people in the world. Back in 2010 we used IE8 for all testing. A few years back we switched to IE9 when it became the most popular browser. Today, Chrome is the most popular browser so we need to switch to Chrome. In discussions with Pat and others in the HTTP Archive forum, we decided to run Chrome and IE9 side-by-side so we could compare the results before making the transition. Therefore, we created HTTP Archive Chrome back in May 2015.
Android: HTTP Archive Mobile processes 5K URLs using real iPhones, but it’s not feasible to scale this up to our goal of 1M URLs. Therefore, we’re evaluating using Chrome to emulate Android devices. In May 2015 we rolled out HTTP Archive Android to start gathering data in order to evaluate making this transition.
Looking Ahead
Our goal from the beginning has been to analyze the world’s top 1 million URLs. In order to do that we need to transition to using Chrome for desktop analysis and Chrome emulation for mobile. Now that we have months of data in HTTP Archive Chrome and HTTP Archive Android, the next step is to validate the results by comparing to the previous IE9 and iPhone results. It’s likely there will be differences, and we need to identify the causes for those differences before making the switch.
In addition to changing our test agents and increasing the number of URLs, we need to upgrade the charting software. We’re also going to focus on some new custom metrics that focus on identifying critical blocking resources.
Please check out these new changes in the HTTP Archive, HTTP Archive Mobile, HTTP Archive Chrome, and HTTP Archive Android. Make sure to search for your website to see your own performance history. If you have your own questions you’d like answered then try using the HTTP Archive dumps that Ilya Grigorik has exported to Google BigQuery and the examples from bigqueri.es. And send any other questions or suggestions to the HTTP Archive forum.